

We often discover more than a handful of strategies to increase the accuracy of machine learning models through parameter optimisation in notebooks and learning materials. In today’s machine learning, data is crucial, yet it’s often overlooked and mishandled in AI projects. As a result, hundreds of hours are wasted refining a model that is based on poor data. That is the primary reason why our model’s accuracy is substantially lower than predicted – and it has nothing to do with model optimisation. Allowing this to happen is not a good idea. One plausible explanation is that the AI community follows academic research in AI. Working on data is sometimes considered a low-skill endeavour or a boring job and many engineers prefer to concentrate on models instead.
Data-centric and Model-centric are the two main components of any AI system, and they work together to provide the desired outcomes. Libraries allow us to write less code for the same outcomes, but no one can teach us how to properly prepare the data. Fortunately, times have changed, and some influential people in the field, such as Dr. Andrew Ng, have begun to implement new paradigms by concentrating on data. “Examining a sample of recent publications revealed that 99% of the papers were model-centric with only 1% being data-centric”, said Andrew Ng. Now, let’s start by finding out the concept:
ML is an iterative process to improve a model’s performance by collecting as much data as we can and optimising the model so it can deal with noise in the data. The model-centric approach focuses on enhancing the model’s training method, coding, and architecture.
The data-centric approach, with an aim to encourage purposeful systematic engineering approaches to improve data in more reliable, precise, and efficient ways.
The importance of Data-centric
On March 25th 2021, Andrew Ng’s “Data-centric AI webinar” covered the advantages of a larger investment in data preparation, with his team demonstrating that investing in enhanced existing data quality is as beneficial as gathering three times the quantity of data. Because data is consuming the globe, Andrew Ng wants to ensure that the world’s data is of the highest quality possible. “Data is food for AI”, argues Ng, who is initiating a push to redirect AI practitioners’ attention away from model/algorithm development and toward the quality of data they use to train models. “When a system isn’t performing well, many teams instinctually try to improve the code. But for many practical applications, it’s more effective instead to focus on improving the data,” he said.
One of the examples presented during the session was “inspecting sheets for detects”— assuming a sequence of photos from steel sheets, factory operators want to construct the best model to recognise these problems that can occur during the production process of steel sheets. They want to be able to recognise 39 distinct types of faults. It was able to establish a 76.2 percent accuracy baseline system by constructing a computer vision model with well-tuned hyper-parameters, but the aim is to attain 90 percent accuracy. How can this be accomplished?
Knowing that the baseline model was already good, improving it to 90 percent accuracy seems nearly impossible — for the model-centric, but using a data-centric approach about two weeks, it’s getting 93.1 percent of accuracy in this project by improving the quality of the data. The results were incredible. Besides, some other examples also bring effective outcomes thanks to good data sources.
| Steel defect detection | Solar panel | Surface Inspection | |
| Baseline | 76.2% | 75.68% | 85.05% |
| Model-centric | +0%
(76.2%) |
+0.04%
(75.72%) |
+0%
(85.05%) |
| Data-centric | +16.9%
(93.1%) |
+3.06%
(78.74%) |
+0.4%
(85.45%) |
To summarise, do not attempt to outsmart a group of PhDs. Instead, make sure your data is of the highest quality possible before attempting to enhance the model.
Features of data
More data does not always imply better data. There are three primary features of data:
Volume
The amount of data is critical, you must have enough data to solve your problem. Deep Networks are low-bias, high-variability computers, and we believe that additional data is the solution to the variance problem. However, the technique of accumulating more data haphazardly maybe both data-efficient and costly. Before beginning on a journey to find new data, we must first determine what type of data we need to add. This is normally accomplished by analysing the present model’s errors.
How much data is enough? That is more difficult to answer. In the documentation for most algorithms, there will be a minimum suggested number of data points. YOLOv5, for example, suggests at least 1500 photos for each class. To summarise — having an abundance of data is a perk, not a necessity.
Consistency
Consistency in data annotation is critical since any discrepancy might derail the model and render your evaluation untrustworthy. A new study finds that around 3.4 percent of instances infrequently used datasets were mislabeled, and that larger models are more affected by this.

The above example demonstrates how readily inconsistent human labelling might enter into your data collection. None of the annotations above are incorrect; they are just inconsistent with one another, which might confound the learning system. As a result, we must carefully create annotation instructions to ensure uniformity. The machine learning engineer must be well familiar with the dataset.
Quality
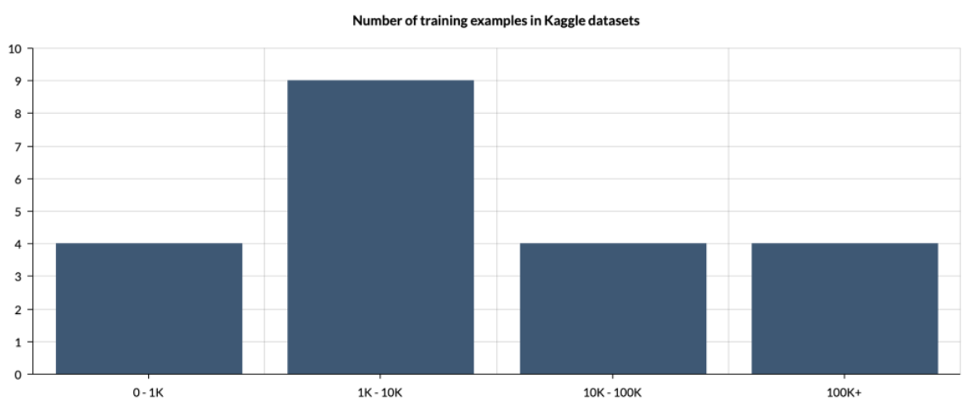
As you can see, most datasets aren’t that large. In a data-centric approach, the size of the dataset is unimportant. In fact, you can’t train a neural network on three photos, but the emphasis is on quality rather than a number.
In conclusion, we’ll now look at two places where you can get high-quality datasets for free. The first is well-known in the data science community, whereas the second is a newbie who specialises in certain areas – Kaggle. It’s a well-known site for locating datasets of any type — tabular, picture, and so on.
Original article at Blueeye.ai: https://blog.blueeye.ai/data-centric-trend-in-ai-community/








{kind=link}